A file system manages files and folders for data storage, while a database system organizes structured data for efficient retrieval and manipulation.
TL;DR File System And Database System
A file system is a method used by an operating system to organize and store data on a storage device. It provides a hierarchical structure, with files and folders organized in a tree-like format.
File systems primarily handle individual files, their naming, storage, and retrieval. This system is commonly used for managing documents, media files, and other types of user-generated content.
A database system is a software application that allows for efficient and structured storage, retrieval, and manipulation of data. It employs a data model to represent relationships between data entities and defines rules for data integrity.
Database systems enable users to query and manipulate data using structured query language (SQL). They are commonly used in applications that require complex data management, such as enterprise systems, web applications, and scientific research.
What is a File System?
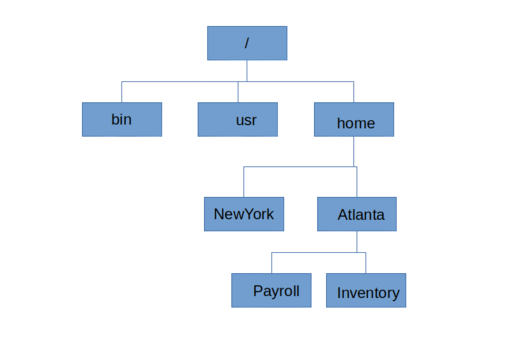
A file system is a method used by operating systems to organize and store data on storage devices such as hard drives, solid-state drives, and external storage devices. It provides a way to manage and access files and directories in a hierarchical structure.
Key characteristics of a file system include:
- File Organization: A file system organizes data into files and directories. Files contain data, while directories serve as containers for files and other directories, forming a hierarchical structure.
- Metadata: Each file in a file system is associated with metadata, which includes information like the file name, size, permissions, creation date, and last modified date. This metadata helps track and manage files.
- Access Control: File systems provide mechanisms to control access to files and directories, determining who can read, write, or execute them.
- File Naming: File systems enforce rules and conventions for naming files, such as character limitations and restrictions on certain special characters.
- File Storage: File systems define how data is stored on storage devices, including the allocation of disk space, management of free space, and file fragmentation.
- File System Types: Different operating systems use various file system types, such as FAT32, NTFS, HFS+, and ext4. Each file system type has its own features, limitations, and compatibility.
A file system is a fundamental component of an operating system that manages the organization, storage, and access of files and directories on storage devices.
How Does a File System Work?
Unlocking the inner workings of a file system, let’s dive into its fascinating mechanics. Discover how data is organized, and explore the intricate web of file naming and storage. Get ready to uncover the secrets behind how file systems make sense of the chaos, and unleash the power of efficient data management. It’s time to demystify the magic that powers our digital world.
Organization and Structure of Data
The systematic approach to managing and storing information is crucial when it comes to the organization and structure of data. A table is a useful tool for visually representing the organization and structure of data, facilitating easy understanding and access to the necessary details.
Column 1
Column 2
Column 3
| Data Category A | Data Category B | Data Category C |
| Data Item 1 | Data Item 1 | Data Item 1 |
| Data Item 2 | Data Item 2 | Data Item 2 |
| Data Item 3 | Data Item 3 | Data Item 3 |
The table above provides an example of how data can be organized and structured. It clearly demonstrates the different data categories in the first row and the corresponding data items in the subsequent rows. This organization greatly simplifies the management and retrieval of data, saving time and effort.
Pro-tip: When organizing and structuring data, it is important to ensure that each data item is accurately placed in the appropriate category, maintaining clarity and improving searchability. Consider using descriptive labels for columns and rows to enhance understanding and usability.
File Naming and Storage
- When it comes to file naming in a file system, it is crucial to consider the aspect of File Naming. It is important to choose descriptive and meaningful names for your files to ensure easy file identification and location. This can greatly contribute to the overall organization and accessibility of files in the system. It is advisable to avoid using special characters or spaces in file names, as they can cause compatibility and portability issues.
- Another key aspect in a file system is File Storage. Files are stored in directories or folders, which can have a hierarchical structure. This hierarchical organization allows for efficient management and organization of files. Proper consideration must be given to the available storage space when storing files, and it should be allocated appropriately to ensure efficient utilization.
In a file system, the practices of File Naming and Storage significantly impact the overall organization and accessibility of files. By choosing descriptive and meaningful file names, users can easily locate and retrieve the necessary information. Implementing efficient file storage practices also ensures the optimal utilization of available storage space.
What is a Database System?

A database system is a software application or a set of software tools that allows users to store, manage, and organize large amounts of data efficiently and effectively. It provides a structured approach to store, retrieve, update, and delete data in a systematic manner.
A database system consists of two main components:
- Database: A database is a collection of related data that is organized and structured to serve a specific purpose. It stores data in tables, which consist of rows (records) and columns (attributes). The database holds the actual data and provides a logical structure for accessing and managing it.
- Database Management System (DBMS): The DBMS is the software that allows users to interact with the database. It provides a set of tools and functions to create, modify, and query the database. The DBMS handles tasks such as data storage, data retrieval, data security, data integrity, and concurrency control.
A database system offers several advantages over traditional file systems:
- Data Independence: The database system provides data independence, which means that the physical storage details of the data are abstracted away from the users. This allows for easier modification and maintenance of the database without affecting the applications that use the data.
- Efficient Data Access: With a database system, data can be accessed and retrieved efficiently using powerful query languages like SQL. Users can retrieve specific information from large datasets quickly and accurately.
- Data Integrity and Security: Database systems enforce data integrity rules and provide mechanisms for maintaining data consistency. They also offer security features to protect sensitive data from unauthorized access.
- Concurrent Access and Data Sharing: Multiple users can access and modify the database simultaneously without conflicts or data inconsistency. The DBMS handles concurrent access and provides mechanisms for data sharing and collaboration.
- Data Recovery and Backup: Database systems offer features for data backup and recovery in case of system failures or data loss. Regular backups can be taken to ensure the safety and availability of data.
A database system is a software application that manages and organizes large amounts of data in a structured manner, providing users with efficient data access, data integrity, security, and other advanced features.
How Does a Database System Work?
Curious about the inner workings of a database system? In this section, we’ll delve into how a database system functions, uncovering the secrets behind data modeling and structuring, and the intriguing world of querying and manipulating data. Prepare to be amazed as we explore the behind-the-scenes magic that powers the storage, organization, and retrieval of information in the realm of databases.
Data Modeling and Structuring
Data modeling and structuring are crucial aspects of database systems. They involve designing the organization and structure of data in a logical and efficient manner.
| Data Modeling and Structuring |
|---|
| 1. Entity-Relationship Diagrams (ERD) |
| 2. Table Creation |
| 3. Defining Primary and Foreign Keys |
| 4. Normalization |
| 5. Establishing Relationships Between Tables |
| 6. Indexing |
Data modeling involves creating an Entity-Relationship Diagram (ERD) to identify and define the entities (tables) within the database. This helps in visualizing the relationships between different entities and understanding the data flow.
Once the entities are defined, tables are created to store the data. Each table represents a specific entity and includes columns to define the attributes or properties of that entity.
Primary keys are used to uniquely identify each record in a table, while foreign keys establish relationships between tables, ensuring data integrity and referential integrity.
Normalization is applied to eliminate data redundancy and improve efficiency. It involves organizing the data into different normal forms to minimize data duplication.
Establishing relationships between tables is done through primary key-foreign key relationships. This allows for efficient querying and manipulation of data.
Indexing is used to enhance the performance of database operations by creating indexes on specific columns, which speeds up the retrieval of data.
Data modeling and structuring play a fundamental role in organizing and optimizing the data within a database system, ensuring data integrity and efficient data retrieval.
Querying and Manipulating Data
To effectively query and manipulate data in a database system, you need to have a solid understanding of the process and perform various operations and commands. These operations, such as SELECT, INSERT, UPDATE, DELETE, JOIN, GROUP BY, ORDER BY, and HAVING, allow you to retrieve, insert, modify, and remove data based on specific conditions or criteria.
To retrieve data from one or more tables based on conditions, you use the SELECT operation. For inserting new data into a table, you utilize the INSERT operation. If you need to modify existing data in a table, the UPDATE operation comes into play. To remove data from a table, you can rely on the DELETE operation.
If you want to combine data from two or more tables based on a common column, the JOIN operation is used. The GROUP BY operation allows you to group data based on a specific column, while the ORDER BY operation sorts data in either ascending or descending order. The HAVING operation helps you filter grouped data based on conditions.
By understanding the structure and data modeling of the database system, as well as the SQL language, you can effectively perform complex data manipulations. Combining different commands and tables allows you to extract the required information, add new data, update existing records, and remove unnecessary data from the database. These operations are crucial for tasks like analysis and reporting.
To master querying and manipulating data, it is important to practice with sample databases, study SQL documentation and tutorials, and seek guidance from experienced professionals or online communities dedicated to database management. Continuously improving your skills in this area will make you proficient in deriving meaningful insights from data and making informed decisions.
What are the Differences between File System and Database System?
When it comes to data management, understanding the differences between file systems and database systems is crucial. In this section, we’ll dive into the contrasting characteristics of these two systems. From data organization to flexibility and scalability, we’ll explore how each system holds its own advantages and disadvantages. We’ll touch upon data integrity and the ease of data sharing and access, shedding light on which system excels in which areas. Get ready to unveil the secrets behind these fundamental components of the digital world!
Data Organization
The organization of data is a crucial aspect of both file systems and database systems. In order to understand the differences between the two, let’s consider how data organization works in each system.
| File System | Database System |
| In a file system, data organization is based on files and directories. Files are stored in directories, which can be organized in a hierarchical structure. | In a database system, data organization is based on tables, which consist of rows and columns. Each table represents a specific entity or concept, and rows contain individual instances or records. Columns define the attributes or properties of the entity. |
| The structure of the data in a file system is determined by the file formats and file types. Each file can have its own structure and organization. | In a database system, the structure of the data is defined by the database schema. The schema specifies the tables, their relationships, and the constraints on the data. |
| Accessing and retrieving data in a file system is usually done by navigating through directories and opening files directly. | In a database system, data is accessed using structured query language (SQL) queries. These queries can retrieve specific data based on conditions or perform complex operations on the data. |
Data organization in file systems is more flexible and suited for unstructured data, while database systems provide a structured and organized approach for managing large amounts of data.
Data Integrity
Data integrity is a critical aspect of a Database System and ensures the accuracy, consistency, and reliability of data. It refers to maintaining the integrity, reliability, and correctness of data throughout its lifecycle. To understand the importance of data integrity, let’s look at a table that illustrates the concept:
| Data | Before | After |
| Customer Name | John | John |
| Order Date | 2022-05-10 | 2022-05-10 |
| Product | Laptop | Mobile |
| Price | $1000 | $900 |
In this example, data integrity ensures that the data stays consistent and reliable. If the price of the product is changed from $1000 to $900, for instance, data integrity ensures that all related records are updated accordingly and that the correct price is reflected in the database. This prevents discrepancies or inaccuracies in the data.
Data integrity also includes enforcing data constraints, such as ensuring that no duplicate or null values are entered. It safeguards the quality of data, preventing data corruption, loss, or unauthorized modifications.
Data integrity considerations extend to maintaining the privacy and security of data, protecting it from unauthorized access or manipulation. Implementing proper security measures, encryption, and access controls helps ensure data integrity.
Data integrity in a Database System guarantees the accuracy, consistency, and reliability of data, preventing errors and maintaining the quality and trustworthiness of the information it stores.
Flexibility and Scalability
- Flexibility: Database systems offer greater flexibility compared to file systems. With a database system, you can easily modify the structure of the database to accommodate changes in data requirements. This means that as your business evolves and grows, you can add or remove fields, tables, and relationships as needed, demonstrating the flexibility of the database. In contrast, file systems are more rigid and require manual adjustments to accommodate changes.
- Scalability: Database systems are designed to handle large amounts of data and are highly scalable. They can efficiently manage and process increasing amounts of data without significant performance degradation, showcasing their scalability. Databases can be distributed across multiple servers to handle high traffic and ensure reliability. On the other hand, file systems may struggle to scale up as the volume of data grows, leading to slower access times and potential data management challenges.
- Data partitioning: In database systems, data can be partitioned across multiple physical storage devices, allowing for better performance and improved availability. This means that different portions of the database can be stored on different servers, enabling parallel processing and faster retrieval of data. File systems, on the other hand, do not typically offer the same level of data partitioning capabilities.
- Concurrency control: Database systems provide mechanisms to manage concurrent access to data by multiple users or applications. They ensure data integrity and prevent conflicts when multiple users try to modify the same data simultaneously. File systems, on the other hand, do not usually provide sophisticated concurrency control mechanisms, making them less flexible and scalable compared to database systems.
Data Sharing and Access
Data sharing and access are crucial for efficient and collaborative work in both database systems and file systems. However, there are key differences between the two:
- File systems typically limit data sharing and access to individual files or directories. Users can control access to their own files through permissions, but collaboration requires manual coordination and file sharing.
- On the other hand, in a database system, data sharing and access are more centralized and structured. Multiple users can access and modify data simultaneously, enabling real-time collaboration and ensuring data consistency.
- File systems rely on file-level locking mechanisms to prevent conflicts when multiple users attempt to access and modify the same file. However, this can cause delays and reduced productivity during collaborative work.
- In contrast, database systems utilize transaction management and concurrency control mechanisms to handle multiple user interactions with the data. This allows for efficient and concurrent data sharing and access, minimizing conflicts and ensuring data integrity.
- File systems lack built-in mechanisms for data versioning, auditing, and access control enforcement beyond traditional file permissions.
- Database systems, on the other hand, offer advanced features such as version control, audit trails, and granular access control mechanisms. These enable organizations to track and manage changes to data, enforce security policies, and comply with regulations.
- Database systems provide a more robust and efficient platform for data sharing and access, particularly in collaborative settings where multiple users require simultaneous access to data.
Frequently Asked Questions
What is the difference between a file system and a database system?
A file system is used for storing arbitrary and unrelated data, while a database system is used for storing structured data in an efficient manner. The main difference lies in the way data is stored and organized.
How does a file system handle data compared to a database system?
A file system organizes and manages files on a storage medium, categorizing and sorting them for easy access. On the other hand, a database system eliminates redundancy, maintains consistency, and saves storage space by storing data in a structured and systematic way.
What advantages does a database system have over a file system?
A database system offers advantages such as tables that are related to each other, the ability to use SQL query/data processing language, efficient query processing, transaction processing, data integrity, concurrency management, robust security, backup, and recovery features.
When is a file system more suitable than a database system?
A file system may be more efficient for handling small data sets with unrelated data. For example, if you are storing JPG pictures and only need to access them using one key, a well-thought-out file system storage may be a better option.
Can a file system handle complex operations like a database system?
While a file system can handle simple operations and finding specific files, it can be slow for complex operations. On the other hand, a database system is designed to efficiently manipulate databases, perform structured queries, and manage large volumes of data.
What are the advantages of using a database management system (DBMS) over a file processing system (FPS)?
A DBMS ensures data consistency, accessibility, security, and recovery. It eliminates redundancy, maintains consistency, and provides efficient access to data through queries. It also offers data integrity, concurrency management, robust security, backup, and recovery features.
Image Credits
Featured Image By – pikisuperstar on Freepik
Image 1 By – Peter Flass, CC BY-SA 4.0 , via Wikimedia Commons
Image 2 By – Chiffre01, CC BY-SA 4.0, via Wikimedia Commons